View Operations
Views create indexes on your information that enable search and select operations on the data.
All views within Couchbase operate as follows:
-
Views are updated as the document data is updated in memory. There may be a delay between the document being created or updated and the document being updated within the view depending on the client-side query parameters.
-
Documents that are stored with an expiry are not automatically removed until the background expiry process removes them from the database. This means that expired documents may still exist within the index.
-
Views are scoped within a design document, with each design document part of a single bucket. A view can only access the information within the corresponding bucket.
-
View names must be specified using one or more UTF-8 characters. You cannot have a blank view name. View names cannot have leading or trailing white-space characters (space, tab, newline, or carriage-return).
-
Document IDs that are not UTF-8 encodable are automatically filtered and not included in any view. The filtered documents are logged so that they can be identified.
-
If you have a long view request, use POST instead of GET.
-
Views can only access documents defined within their corresponding bucket. You cannot access or aggregate data from multiple buckets within a given view.
-
Views are created as part of a design document, and each design document exists within the corresponding named bucket.
-
Each design document can have 0-n views.
-
Each bucket can contain 0-n design documents.
-
-
All the views within a single design document are updated when the update to a single view is triggered. For example, a design document with three views updates all three views simultaneously when one view is updated.
-
Updates can be triggered in two ways:
-
At the point of access or query by using the
staleparameter. -
Automatically by Couchbase Server based on the number of updated documents, or the period since the last update. Automatic updates can be controlled either globally, or individually on each design document.
-
-
Views are updated incrementally. The first time the view is accessed, all the documents within the bucket are processed through the map/reduce functions. Each new access to the view only processes the documents that have been added, updated, or deleted, since the last time the view index was updated.
In practice, this means that views are entirely incremental in nature. Updates to views are typically quick as they only update changed documents. Ensure that views are updated by using either the built-in automatic update system, through client-side triggering, or explicit updates within your application framework.
-
The view update process is incremental by nature. The information is only appended to the index stored on the disk making sure that the index gets updated efficiently. Compaction (including auto-compaction) will optimize the index size on disk and optimize the index structure. An optimized index is more efficient to be updated and queried.
-
The entire view is recreated if the view definition has changed. Because this would have a detrimental effect on live data, only development views can be modified.
Design documents organize views, and indexes are created according to the design document. If you change a single view in a design document that contains multiple views, you will invalidate all the views and stored indexes within the design document. You will then have to rebuild all corresponding views defined in that design document. Rebuilding of the index will increase the I/O across the cluster, in addition to the I/O required for any active production views.
-
You can choose to update the result set from a view before you query it or after you query. Or you can choose to retrieve the existing result set from a view when you query the view. In this case, the results are possibly out of date, or stale.
-
The views engine creates an index is for each design document; this index contains the results for all the views within that design document.
-
The index information stored on disk consists of the combination of both the key and value information defined within your view. The key and value data is stored in the index so that the information can be returned as quickly as possible. Views can then include a reduce function and return the reduced information by extracting that data from the index.
The value and key information from the defined map function are stored in the index. The overall index size can be larger than the stored data if the emitted key/value information is larger than the original source document data.
How expiration impacts views
Be aware that Couchbase Server does lazy expiration, that is, expired items are flagged as deleted rather than being immediately erased. Couchbase Server has a maintenance process, called expiry pager that periodically looks through all information and erase expired items. The maintenance process runs every 10 minutes, by default, unless configured to run at a different interval. When an item is requested, Couchbase Server removes the item flagged for deletion and provides a response that the item does not exist.
The result set from a view will contain any items stored on disk that meet the requirements of your views function. Therefore, the information not removed from the disk may appear as part of a result set when you query a view.
Using Couchbase views, you can also perform the reduce functions on data, which perform calculations or other aggregations of data. For instance, if you want to count the instances of a type of object, use a reduce function. Once again, if an item is on disk, it will be included in any calculation performed by your reduce functions. Based on this behavior due to disk persistence, here are guidelines on handling expiration with views:
-
Detect expired documents in result sets: The items not removed as part of the expiry pager maintenance process are part of a result set returned by querying the view.
-
Perform aggregations and calculations on data: In some cases, you can perform the
reducefunction to aggregate and calculate data in Couchbase Server. In this case, Couchbase Server takes pre-calculated values stored for an index and derives a final result. Any expired items still on disk will be part of the reduction, which might not be an issue for your final result if the ratio of expired items is proportionately low compared to other items. For instance, if you have ten expired scores still on disk for an average performed over 1 million players, there may be only a minimal level of difference in the final result. However, if you have ten expired scores on disk for an average performed over 20 players, you would get very different result than the average you would expect.Run the expiry pager process more frequently to ensure that items that have expired are not included in calculations used in the reduce function. Do note that this interval will have some slight impact on node performance as it will be performing cleanup more frequently on the node.
For more information about setting intervals for the maintenance process, refer to the Couchbase command-line tool and review the examples on exp_pager_stime.
How views function in a cluster
Distributing data. If you familiar working with Couchbase Server, you know that the server distributes data across different nodes in a cluster. If you have four nodes in a cluster, on average, each node will contain about 25% of active data. If you use views with Couchbase Server, the indexing process runs on all four nodes, and the four nodes will contain roughly 25% of the results from indexing on disk. This index is called a partial index since it is based on a subset of data within a cluster (shown in the illustration).
Replicating data and Indexes. Couchbase Server also provides data replication; this means that the server will replicate data from one node to another node. In case the first node fails the second node can still handle requests for the data. To handle possible node failure, you can specify that Couchbase Server also replicate a partial index for replicated data. By default, each node in a cluster will have a copy of each design document and view functions. If you make any changes to a views function, Couchbase Server will replicate this change to all nodes in the cluster. The sever will generate indexes from views within a single design document and store the indexes in a single file on each node in the cluster:
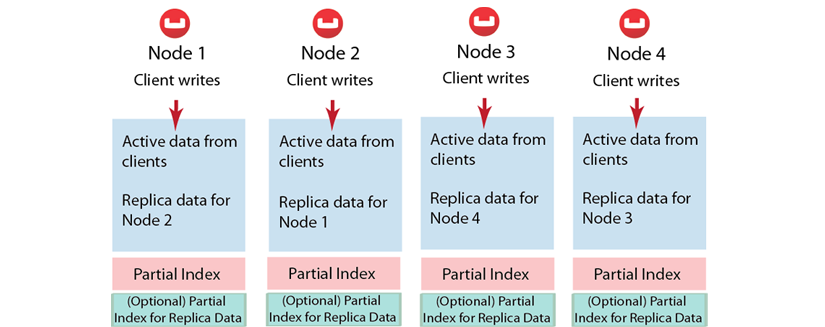
Couchbase Server can optionally create replica indexes on nodes that contain replicated data; this is to prepare your cluster for a failover scenario. The server does not replicate index information from another node. Instead, each node creates an index for the replicated data it stores. The server recreates indexes using the replicated data on a node for each defined design document and view. By providing replica indexes, the server enables you to perform queries even in the event of node failure. You can specify whether Couchbase Server creates replica indexes or not when you create a data bucket.
Query Time within a Cluster
When you query a view and thereby trigger the indexing process, you send that request to a single node in the cluster. This node then distributes the request to all other nodes in the cluster. Depending on the parameter sent in your query, each node will either send the most current partial index at that node, will update the partial index and send it, or send the partial index and update it on disk. Couchbase Server will collect and collate these partial indexes and send this aggregate result to a client.
To handle errors when you perform a query, you can configure how the cluster behaves when errors occur.
Queries During Rebalance or Failover
You can query an index during cluster rebalance and node failover operations. If you perform queries during rebalancing or node failure, Couchbase Server will ensure that you receive the query results that you would expect from a node as if there were no rebalance or node failure.
During node rebalancing, you will get the same results you would get as if the data were active data on a node and as if data were not being moved from one node to another. In other words, this feature ensures you get query results from a node during rebalancing that are consistent with the query results you would have received from the node before rebalance started. This functionality operates by default in Couchbase Server. However, you can optionally choose to disable it.
If querying of indexes during cluster rebalancing and node failover is enabled, cluster rebalancing will take more time. However, it is not recommended that you disable this functionality in production without thorough testing or you might observe inconsistent query results.
View performance
View performance includes the time taken to update the view, the time required for the view update to be accessed, and the time for the updated information to be returned, depend on different factors. Your file system cache, frequency of updates, and the time between updating document data and accessing (or updating) a view will all impact performance.
Some key notes and points are provided below:
-
Index queries are always accessed from disk; indexes are not kept in RAM by Couchbase Server. However, frequently used indexes are likely to be stored in the filesystem cache used for caching information on disk. Increasing your filesystem cache, and reducing the RAM allocated to Couchbase Server from the total RAM available will increase the RAM available for the OS.
-
The filesystem cache will play a role in the update of the index information process. Recently updated documents are likely to be stored in the filesystem cache. Requesting a view update immediately after an update operation will likely use information from the filesystem cache. The eventual persistence nature implies a small delay between updating a document, it being persisted, and then being updated within the index.
Keeping some RAM reserved for your operating system to allocate filesystem cache, or increasing the RAM allocated to filesystem cache, will help keep space available for index file caching.
-
View indexes are stored, accessed, and updated, entirely independently of the document updating system. The index update and retrieval are not dependent on documents in memory to build the index information. Separate systems also mean that the performance, when retrieving and accessing the cluster, is not dependent on the document store.
Index updates and the stale parameter
Indexes are created by Couchbase Server based on the view definition, but updating of these indexes can be controlled at the point of data querying, rather than each time data is inserted.
Whether the index is updated when queried can be controlled through the stale parameter.
Irrespective of the stale parameter, documents can only be indexed by the system once the document is persisted to the disk.
If the document is not persisted to the disk, use of stale will not force this process.
You can use the observe operation to monitor when documents are persisted to the disk or updated in the index.
Views can also be updated automatically according to a document change, or interval count.
Three values for stale are supported:
-
stale=ok
The index is not updated. If an index exists for the given view, then the information in the current index is used as the basis for the query and the results are returned accordingly.
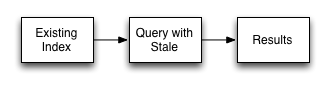
This setting results in the fastest response times to a given query since the existing index is used without being updated. However, this might return incomplete information if changes have been made to the database, and these documents would otherwise be included in the given view.
-
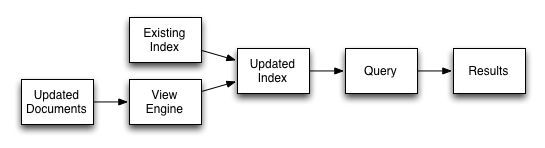
stale=false
The index is updated before you execute the query, making sure that any documents updated and persisted to disk are included in the view. The client will wait until the index has been updated before the query has executed and, therefore, the response will be delayed until the updated index is available.
-
stale=update_after
This is the default setting if no stale parameter is specified.
The existing index is used as the basis of the query, but the index is marked for updating once the results have been returned to the client.
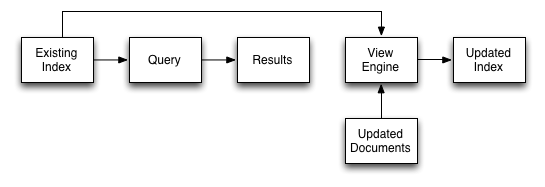
The indexing engine is an asynchronous process; this means querying an index may produce results you may not expect. For example, if you update a document, and then immediately run a query on that document you may not get the new information in the emitted view data. The document updates have not yet been committed to the disk, at which point the updates are indexed.
The deleted documents may appear in the index even after deletion because the deleted document is still not removed from the index.
When you have multiple clients accessing an index, the index update process and results returned to clients depend on the parameters passed by each client and the sequence that the clients interact with the server.
-
Situation 1
-
Client 1 queries view with
stale=false -
Client 1 waits until server updates the index
-
Client 2 queries view with
stale=falsewhile re-indexing from Client 1 still in progress -
Client 2 will wait until existing index process triggered by Client 1 completes. Client 2 gets updated index.
-
-
Situation 2
-
Client 1 queries view with
stale=false -
Client 1 waits until server updates the index
-
Client 2 queries view with
stale=okwhile re-indexing from Client 1 in progress -
Client 2 will get the existing index
-
-
Situation 3
-
Client 1 queries view with
stale=false -
Client 1 waits until server updates the index
-
Client 2 queries view with
stale=update_after -
If re-indexing from Client 1 not done, Client 2 gets the existing index. If re-indexing from Client 1 is done, Client 2 gets this updated index and triggers re-indexing.
-
Index updates may be stacked if multiple clients request the view be updated before the information is returned ( stale=false ).
Multiple clients updating and querying the index data can then get the updated document and version of the view each time.
For stale=update_after queries, there is no stacking, since all updates occur after the query has been accessed.
Sequential accesses
-
Client 1 queries view with stale=ok
-
Client 2 queries view with stale=false
-
View gets updated
-
Client 1 queries a second time view with stale=ok
-
Client 1 gets the updated view version
The above scenario can cause problems when paginating over a number of records as the record sequence might change between individual queries.
Automated index updates
In addition to a configurable update interval, you can also update all indexes automatically in the background.
You configure automated update through two parameters, the update time interval in seconds and the number of document changes that occur before the views engine updates an index.
These two parameters are updateInterval and updateMinChanges.
-
updateInterval: the time interval in milliseconds, the default is 5000 milliseconds. At everyupdateIntervalthe views engine checks if the number of document mutations on disk is greater thanupdateMinChanges. If true, it triggers the view update. The documents stored on disk potentially lag documents that are in-memory for tens of seconds. -
updateMinChanges: the number of document changes that occur before re-indexing occurs, the default is 5000 changes.
The auto-update process only operates on the full-set development and production indexes. Auto-update does not operate on partial set development indexes.
Irrespective of the automated update process, documents can only be indexed by the system once the document has been persisted to disk.
If the document has not been persisted to disk, the automated update process will not force the unwritten data to be written to disk.
You can use the observe operation to monitor when documents have been persisted to disk or updated in the index.
The updates are applied as follows:
-
Active indexes, Production views
For all active, production views, indexes are automatically updated according to the update interval updateInterval and the number of document changes updateMinChanges.
If updateMinChanges is set to 0 (zero), then automatic updates are disabled for main indexes.
-
Replica indexes
If replica indexes have been configured for a bucket, the index is automatically updated according to the document changes ( replicaUpdateMinChanges ; default 5000) settings.
If replicaUpdateMinChanges is set to 0 (zero), then automatic updates are disabled for replica indexes.
The trigger level can be configured both globally and for individual design documents for all indexes using the REST API.
The ddocs allow you to set updateMinChanges or replicaUpdateMinChanges only via options.
The updateInterval can only be set for the whole cluster.
|
To obtain the current view update daemon settings, access a node within the cluster on the administration port using the URL http://nodename:8091/settings/viewUpdateDaemon :
GET http://Administrator:Password@nodename:8091/settings/viewUpdateDaemon
The request returns the JSON of the current update settings:
{
"updateInterval":5000,
"updateMinChanges":5000,
"replicaUpdateMinChanges":5000
}
To update the settings, use POST with a data payload that includes the updated values.
For example, to update the time interval to 10 seconds, and document changes to 7000 each:
POST http://nodename:8091/settings/viewUpdateDaemon updateInterval=10000&updateMinChanges=7000
If successful, the return value is the JSON of the updated configuration.
To configure the updateMinChanges or replicaUpdateMinChanges values explicitly on individual design documents, specify the parameters within the options section of the design document.
For example:
{
"_id": "_design/myddoc",
"views": {
"view1": {
"map": "function(doc, meta) { if (doc.value) { emit(doc.value, meta.id);} }"
}
},
"options": {
"updateMinChanges": 1000,
"replicaUpdateMinChanges": 20000
}
}
You can set this information when creating and updating design documents through the design document REST API.
To perform this operation using the curl tool:
> curl -X POST -v -d 'updateInterval=7000&updateMinChanges=7000' \
'http://Administrator:Password@192.168.0.72:8091/settings/viewUpdateDaemon'
Partial-set development views are not automatically rebuilt. During rebalancing development views are not updated, even when consistent views are enabled, as this relies on the automated update mechanism. Updating development views in this way would waste system resources.