Server Group Awareness
Individual server-nodes can be assigned to specific groups, within a Couchbase Cluster. This allows both active vBuckets and GSI indexes to be maintained on groups different from those of their corresponding replica vBuckets and index replicas; so that if a group goes offline, and active vBuckets and indexes are thereby lost, replicas remain available on one or more other groups.
Understanding Server Group Awareness
Server Group Awareness provides enhanced availability. Specifically, it protects a cluster from large-scale infrastructure failure, through the definition of groups. Each group is created by an appropriately authorized administrator, and specified to contain a subset of the nodes within a Couchbase Cluster. Following group-definition and rebalance, the active vBuckets for any defined bucket are located on one group, while the corresponding replicas are located on another group: indexes and index replicas, maintained by the Index Service, are distributed across groups in a similar way.
A server group can be automatically failed over: thus, if the entire group goes offline, and active vBuckets and indexes are thereby inaccessible, the replica vBuckets and replica indexes that remain available on another group can be automatically promoted to active status. In 7.1+, this is achieved by setting the maximum count for auto-failover to a value equal to or greater than the number of nodes in the server group. See Automatic Failover.
Groups should be defined in accordance with the physical distribution of cluster-nodes. For example, a group should only include the nodes that are in a single server rack, or in the case of cloud deployments, a single availability zone. Thus, if the server rack or availability zone becomes unavailable due to a power or network failure, all the nodes in the group can be automatically failed over, to allow continued access to the affected data.
Note the following:
-
Server Group Awareness is only available in Couchbase Server Enterprise Edition.
-
Server Group Awareness only applies to the Data and Index Services.
-
When a new Couchbase Server cluster is initialized, and no server groups are explicitly defined, the first node, and all subsequently added nodes, are automatically placed in a server group named Group 1. Once additional server groups are created, a destination server group must be specified for every node that is subsequently added to the cluster.
For information on failover, see Failover and Rebalance. For information on vBuckets, see Buckets. For information on the standard (non-Group-based) distribution of replica vBuckets across a cluster, see Availability.
Server Groups and vBuckets
The distribution of vBuckets across groups is exemplified below. In each illustration, all servers are assumed to be running the Data Service.
Equal Groups
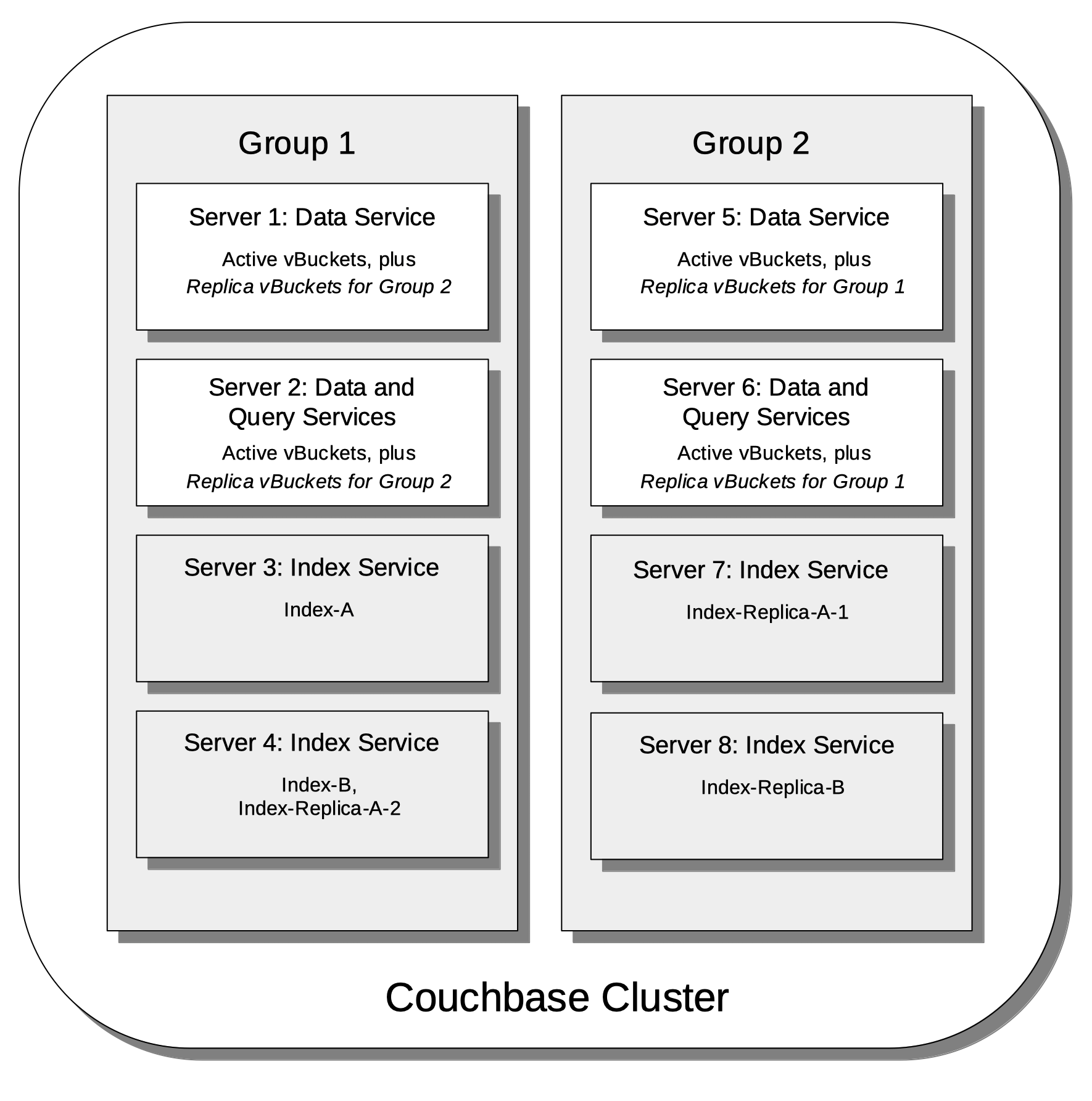
The following illustration shows how vBuckets are distributed across two groups; each group containing four of its cluster’s eight nodes.
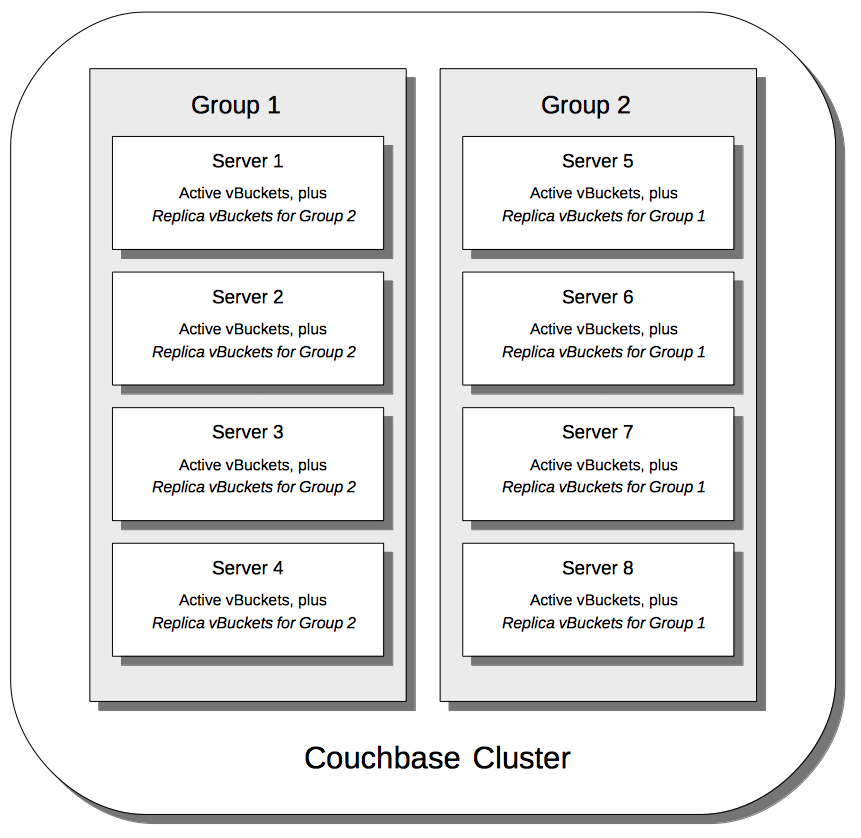
Note that Group 2 contains all the replica vBuckets that correspond to active vBuckets on Group 1; while conversely, Group 1 contains all the replica vBuckets that correspond to active vBuckets on Group 2.
Unequal Groups
A number of constraints come into play when allocating active and replica vBuckets across server groups:
| rack-zone |
all replicas of a given vBucket must reside in separate server groups. |
| active balance |
there should be approximately the same number of active vBuckets on each node in the cluster. |
| replica balance |
there should be approximately the same number of replica vBuckets on each node in the cluster. |
Not all the constraints can be satisfied when the buckets are allocated across uneven groups.
In this scenario, the active balance and rack-zone constraints will take priority:
when the vBucket map is generated, we will ensure that there are approximately the same number of active vBuckets on each cluster and that replicas of a given vBucket must reside in separate groups.
The following illustration shows how vBuckets are distributed across two groups: Group 1 contains four nodes, while Group 2 contains five.
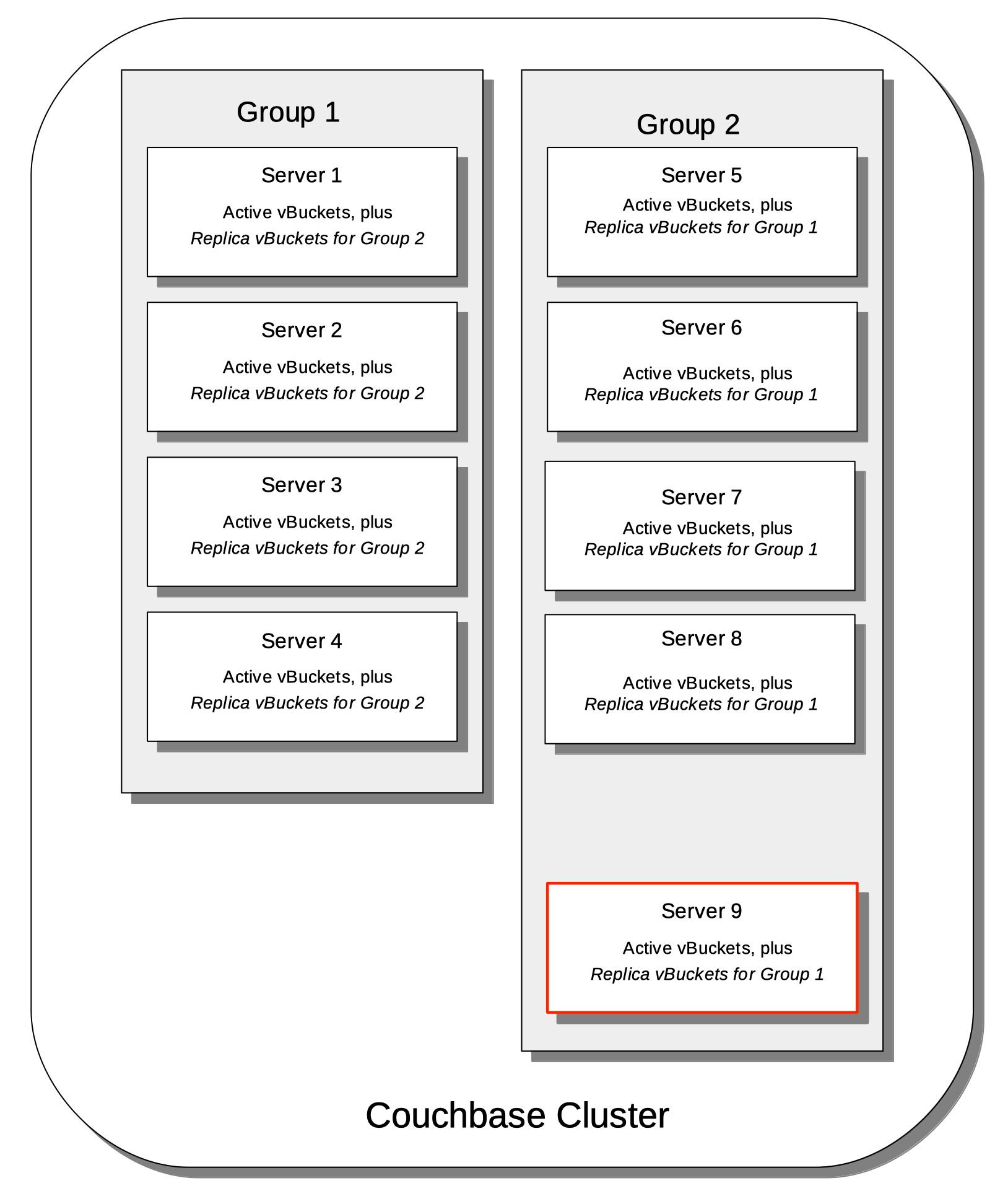
Group 1 contains all the replica vBuckets that correspond to active vBuckets in Group 2.
Group 2 contains all the replica vBuckets that correspond to active vBuckets in Group 1.
However, in order to ensure that replicas of a VBucket must reside in a separate group, then we may have a situation where there are vBuckets from Server 9 replicated to Group 1, but there are no additional vBuckets in Group 1 to provide balance in Group 2.
|
Smaller server groups will carry more replica vBuckets, which means there is greater memory pressure on memcached so more fetches go to disk which means higher worst case GET latencies. Additionally, more replicas mean more writes to disk and a greater compaction burden which will also affect latencies. Customers will notice this as the smaller server groups will "perform" worse than the later server groups. So for reasons of consistency of performance Couchbase strongly recommends that customers endeavor to maintain an equal number of nodes across server groups. |
For more information on optimizing your cluster configuration, consult the Sizing Guidelines.
Node-Failover Across Groups
When an individual node within a group goes offline, rebalance provides a best effort redistribution of replica vBuckets. This keeps all data available, but results in some data being no longer protected by the Groups mechanism. This is shown by the following illustration, in which Server 2, in Group 1, has gone offline, and a rebalance and failover have occurred.
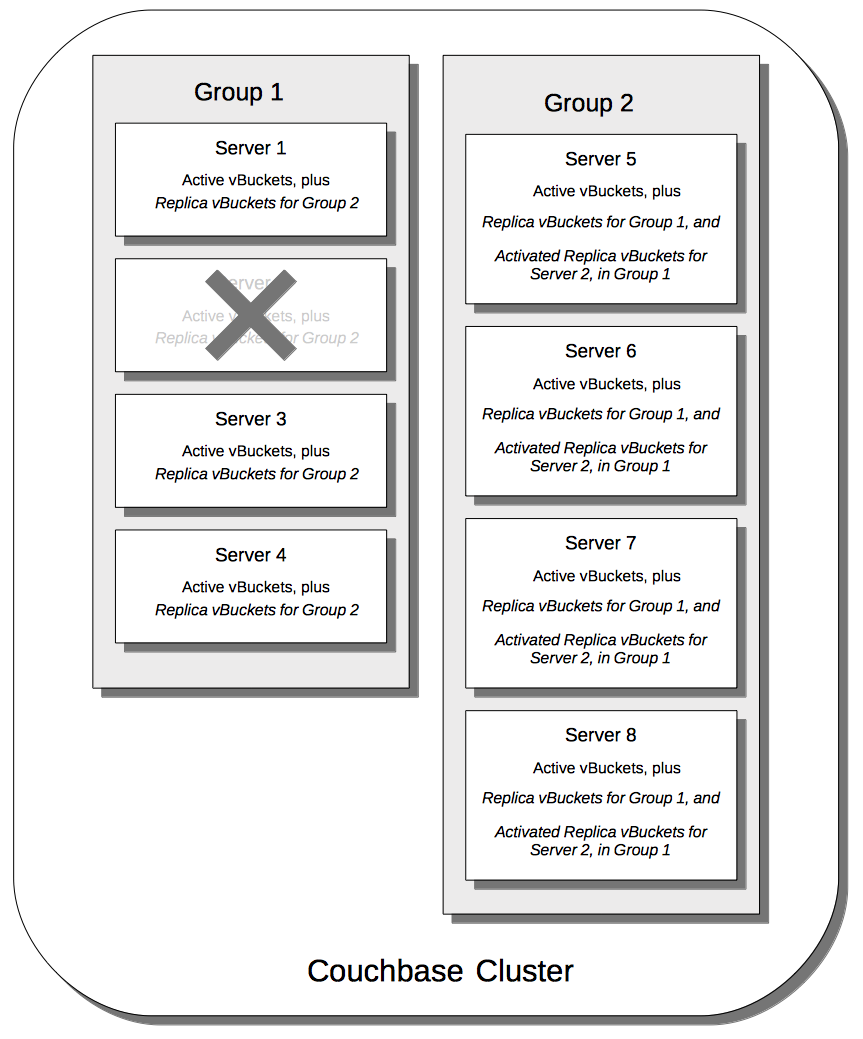
With the active vBuckets on Server 2 no longer accessible, the replica vBuckets for Server 2 have been promoted to active status, on the servers of Group 2. The data originally active on Server 2 is thereby kept available. Note, however, that if Group 2 were now to go offline, the data originally active on Server 2 would be lost, since it now exists only on Group 2 servers.
Server Groups and Indexes
Indexes and index replicas can only be located on nodes that run the Index Service.
As described in Index Replication, the Index Service allows index replicas to be defined in either of two ways:
-
By establishing the number of replicas required, for a given index, without the actual node-locations of the replicas being specified. This is itself accomplished in either of the following ways:
-
By providing, as the argument to the
WITHclause, thenum_replicakey, with an accompanying integer that is the desired number of replicas. -
By specifying the number of index-replicas to be created by the Index Service whenever
CREATE INDEXis invoked.
-
-
By establishing the number of replicas required, for a given index, with the actual node-locations for the index itself and each of its replicas being specified. This is accomplished by providing, as the argument to the
WITHclause, an array of nodes.
Examples of these different forms of replica-definition are provided in Index Replication.
If the node-locations for index and replicas are specified, by means of the WITH clause and node-array, this user-defined topology is duly followed in the locating of index and replicas across the cluster, and any server groups that may have been defined.
In this case, it is the administrator’s responsibility to ensure that optimal index-availability has been achieved, so as to handle possible instances of node or group failure.
If the node-locations for index and replicas are not specified, the node-locations are automatically provided by Couchbase Server, based on its own estimates of how to provide the highest index-availability. Such distributions are exemplified as follows.
Optimal Distribution
When the number of index replicas created for a given index is at least one less than the total number of groups for the cluster, and each group contains sufficient nodes running the Index Server, automatic distribution ensures that each index and index replica resides on its own group. (Indexes and index replicas always exist each on their own Index Server node, with index-creation failing if there is an insufficiency of such nodes to accommodate the specified number of index replicas — see Index Replication.)
For example:
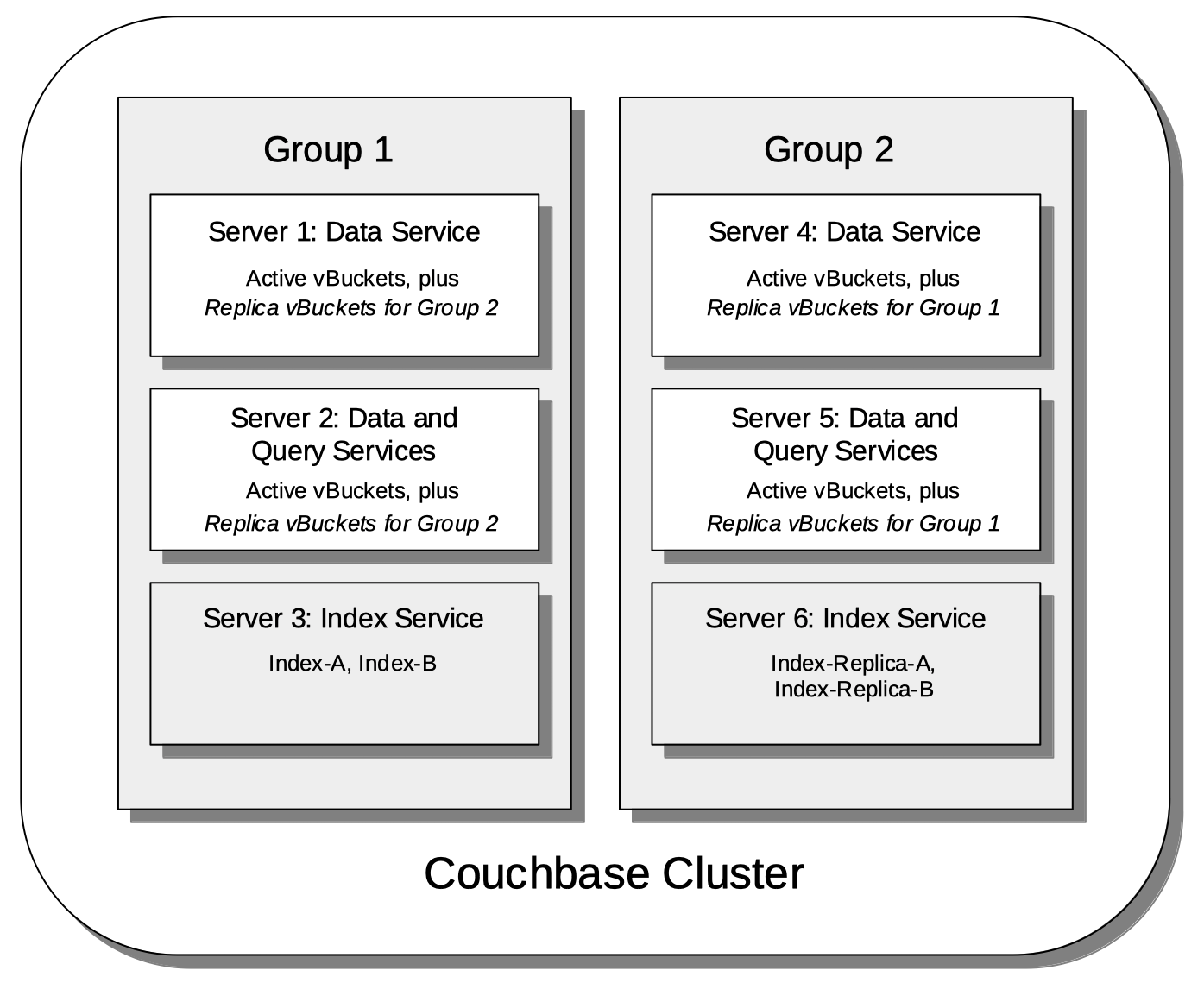
Here, two groups have been defined. Each group contains one Index Server node. Two indexes have been defined, each with one index replica. Therefore, automatic distribution has assigned both indexes to the Index Server node in group 1, and both index replicas to the Index Server node in group 2. This ensures that, should either group become inaccessible, the surviving group continues to bear an instance of the Index Server, with both indexes thus available.
Note that an alternative outcome to the automatic distribution would have been for each index to be assigned to a different group, and each index replica to be assigned to the group on which its corresponding index did not reside.
Best-Effort Distribution
When the number of index replicas created for a given index is not at least one less than the total number of groups for the cluster, but the cluster bears enough Index Server nodes to accommodate all defined indexes and index replicas, automatic distribution produces an outcome based on best effort. For example:
Here, again, two groups have been defined. Each group now contains two Index Server nodes. Two indexes have been defined: one with two index replicas, the other with one. Automatic distribution has assigned each index to its own node in Group 1; and has assigned, for each index, a corresponding index replica to its own node in Group 2. However, since one index has two replicas defined, the second of these has been assigned to the second Index Server node in Group 1. Consequently, an index and one of its replicas have both been assigned to the same group; and will both be lost, in the event of that group becoming inaccessible.
Note that an alternative outcome to the automatic distribution would have been for the second index replica to be assigned to Server 8, in Group 2. Consequently, both the index replicas of one index would be assigned to the same group; and both would be lost, in the event of that group becoming inaccessible.
Adding Multiple Groups
When multiple groups are to be added to a cluster simultaneously, the additions should all be executed on a single node of the cluster: this simplifies the reconfiguration process, and so protects against error.
Group Failover and Service Availability
When groups are defined to correspond to racks or availability zones, all services required for data access — such as the Index Service and the Search Service — should be deployed so as to ensure their own continued availability, during the outage of a rack or zone.
For example, given a cluster:
-
Whose Data Service deployment supports two Server Groups, each corresponding to one of two racks
-
Whose data must be continuously accessed by the Index and Search Services
At a minimum, one instance of the Index Service and one instance of the Search Service should be deployed on each rack.
Defining Groups and Enabling Failover of All a Group’s Nodes
To define and manage groups:
-
With Couchbase Web Console, see Manage Groups.
-
With CLI, see group-manage.
-
With the REST API, see Server Groups API.
To enable the failover of all nodes in a group:
-
With Couchbase Web Console, see the information provided for the General settings panel, in Node Availability.
-
With CLI, see setting-autofailover.
-
With the REST API, see Enabling and Disabling Auto-Failover.
Note that in 7.1+, automatic failover can fail over more than three nodes concurrently: this has permitted the removal of pre-7.1 interfaces that were specific to triggering auto-failover for server groups. Consequently, in order to ensure successful auto-failover of a server group, the maximum count for auto-failover must be established by the administrator as a value equal to or greater than the number of nodes in the server group.
Note that the pre-7.1 interfaces for triggering auto-failover for server groups have been removed from 7.1: therefore, programs that attempt to use the pre-7.1 interfaces with 7.1+ will fail.
See Automatic Failover.